We hope to give here a clear reference of the common data structures. To really learn the language, you should take the time to read other resources. The following resources, which we relied upon, also have many more details:
- Practical CL, by Peter Seibel
- CL Recipes, by E. Weitz, full of explanations and tips,
- the CL standard with – in the sidebar of your PDF reader – a nice TOC, functions reference, extensive descriptions, more examples and warnings (i.e: everything). PDF mirror
- a Common Lisp quick reference
Don’t miss the appendix and when you need more data structures, have a look at the awesome-cl list and Quickdocs.
Lists
The simplest way to create a list is with list:
(list 1 2 3)
but there are more constructors, and you should also know that lists
are made of cons cells.
Building lists. Cons cells, lists.
A list is also a sequence, so we can use the functions shown below.
The list basic element is the cons cell. We build lists by assembling cons cells.
(cons 1 2)
;; => (1 . 2) ;; representation with a point, a dotted pair.
It looks like this:
[o|o]--- 2
|
1
If the cdr of the first cell is another cons cell, and if the cdr of
this last one is nil, we build a list:
(cons 1 (cons 2 nil))
;; => (1 2)
It looks like this:
[o|o]---[o|/]
| |
1 2
(ascii art by draw-cons-tree).
See that the representation is not a dotted pair ? The Lisp printer understands the convention.
Finally we can simply build a literal list with list:
(list 1 2)
;; => (1 2)
or by calling quote:
'(1 2)
;; => (1 2)
which is shorthand notation for the function call (quote (1 2)).
Circular lists
A cons cell car or cdr can refer to other objects, including itself or other cells in the same list. They can therefore be used to define self-referential structures such as circular lists.
Before working with circular lists, tell the printer to recognise them
and not try to print the whole list by setting
*print-circle*
to T:
(setf *print-circle* t)
A function which modifies a list, so that the last cdr points to the
start of the list is:
(defun circular! (items)
"Modifies the last cdr of list ITEMS, returning a circular list"
(setf (cdr (last items)) items))
(circular! (list 1 2 3))
;; => #1=(1 2 3 . #1#)
(fifth (circular! (list 1 2 3)))
;; => 2
The list-length
function recognises circular lists, returning nil.
The reader can also create circular lists, using
Sharpsign Equal-Sign
notation. An object (like a list) can be prefixed with #n= where n
is an unsigned decimal integer (one or more digits). The
label #n# can be used to refer to the object later in the
expression:
'#42=(1 2 3 . #42#)
;; => #1=(1 2 3 . #1#)
Note that the label given to the reader (n=42) is discarded after
reading, and the printer defines a new label (n=1).
Further reading
- Let over Lambda section on cyclic expressions
car/cdr or first/rest (and second… to tenth)
(car (cons 1 2)) ;; => 1
(cdr (cons 1 2)) ;; => 2
(first (cons 1 2)) ;; => 1
(first '(1 2 3)) ;; => 1
(rest '(1 2 3)) ;; => (2 3)
We can assign any new value with setf.
last, butlast, nbutlast (&optional n)
return the last cons cell in a list (or the nth last cons cells).
(last '(1 2 3))
;; => (3)
(car (last '(1 2 3)) ) ;; or (first (last …))
;; => 3
(butlast '(1 2 3))
;; => (1 2)
In Alexandria, lastcar is equivalent of (first (last …)):
(alexandria:lastcar '(1 2 3))
;; => 3
reverse, nreverse
reverse and nreverse return a new sequence.
nreverse is destructive. The N stands for non-consing, meaning
it doesn’t need to allocate any new cons cells. It might (but in
practice, does) reuse and modify the original sequence:
(defparameter mylist '(1 2 3))
;; => (1 2 3)
(reverse mylist)
;; => (3 2 1)
mylist
;; => (1 2 3)
(nreverse mylist)
;; => (3 2 1)
mylist
;; => (1) in SBCL but implementation dependent.
append, nconc (and revappend, nreconc)
append takes any number of list arguments and returns a new list
containing the elements of all its arguments:
(append (list 1 2) (list 3 4))
;; => (1 2 3 4)
The new list shares some cons cells with the (3 4):
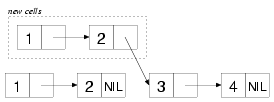
nconc is the recycling equivalent.
revappend and nreconc are two functions you might not use often :)
revappend does (append (reverse x) y):
(revappend (list 1 2 3) (list :a :b :c))
;; => (3 2 1 :A :B :C)
nreconc does (nconc (nreverse x) Y):
(nreconc (list 1 2 3) (list :a :b :c))
;; => (3 2 1 :A :B :C)
You will thank us later.
push, pushnew (item, place)
push prepends item to the list that is stored in place, stores
the resulting list in place, and returns the list.
pushnew is similar, but it does nothing if the element already exists in the place.
See also adjoin below that doesn’t modify the target list.
(defparameter mylist '(1 2 3))
(push 0 mylist)
;; => (0 1 2 3)
(defparameter x ’(a (b c) d))
;; => (A (B C) D)
(push 5 (cadr x))
;; => (5 B C)
x
;; => (A (5 B C) D)
push is equivalent to (setf place (cons item place )) except that
the subforms of place are evaluated only once, and item is evaluated
before place.
There is no built-in function to add to the end of a list. It is a
more costly operation (have to traverse the whole list). So if you
need to do this: either consider using another data structure, either
just reverse your list when needed.
pushnew accepts key arguments: :key, :test, :test-not.
pop
a destructive operation.
nthcdr (index, list)
Use this if first, second and the rest up to tenth are not
enough.
car/cdr and composites (cadr, caadr…) - accessing lists inside lists
They make sense when applied to lists containing other lists.
(caar (list 1 2 3)) ==> error
(caar (list (list 1 2) 3)) ==> 1
(cadr (list (list 1 2) (list 3 4))) ==> (3 4)
(caadr (list (list 1 2) (list 3 4))) ==> 3
destructuring-bind (parameter*, list): pattern matching
This macro does simple pattern matching on lists.
From a declaration of parameters, it binds each parameter to its value taken from the input list.
We can destructure lists and nested lists, with a fixed or a variable
number of elements, we can provide defaults to absent elements, and we
can match the keys of property lists, using the lambla list keywords
we know from a defun or a defmacro: &key, &rest,
&allow-other-keys, etc.
Example:
(destructuring-bind (x y z)
(list 1 2 3)
(format t "x= ~s, y= ~s, z= ~s" x y z))
;; x= 1, y= 2, z= 3
On this example we want to match exactly (x y z), so the list we
match on must provide x, y and z.
Below we make the presence of z optional. Now we can match againt a
list of 2 elements and a list of 3 elements:
(destructuring-bind (x y &optional z)
(list 1 2)
(format t "x= ~s, y= ~s, z=~s" x y z))
;; x= 1, y= 2, z=NIL
But if we wanted to match against a list of a variable number of arguments, it wouldn’t work:
;; DOESN't WORK:
(destructuring-bind (x y &optional z)
(list 1 2 3 4 5)
(format t "x= ~s, y= ~s, z=~s" x y z))
we get an error:
Error while parsing arguments to DESTRUCTURING-BIND:
too many elements in
(1 2 3 4 5)
to satisfy lambda list
(X Y &OPTIONAL Z):
between 1 and 3 expected, but got 5
We can bind the variable number of elements to z with &rest. Now
z is bound to a list:
(destructuring-bind (x y &rest z)
(list 1 2 3 4 5)
(format t "x= ~s, y= ~s, z=~s" x y z))
;; x= 1, y= 2, z=(3 4 5)
The &whole parameter is bound to the whole list. It must be the
first one and others can follow:
(destructuring-bind (&whole whole-list x y &optional z)
(list 1 2 3)
(format t "x= ~s, y= ~s, z=~s, whole list: ~s" x y z whole-list))
;; x= 1, y= 2, z=3, whole list: (1 2 3)
We can match inside sublists:
(destructuring-bind (x (y1 y2) z)
(list 1 (list 2 20) 3)
(list :x x :y1 y1 :y2 y2 :z z))
;; => (:X 1 :Y1 2 :Y2 20 :Z 3)
Another useful feature is destructuring a plist, a list alternating a keyword and a value. We can tell what keys to match, and they can appear in any order in the input:
(destructuring-bind (&key a b c)
(list :c 3 :b 2 :a 1)
(format t "a= ~s, b= ~s, c=~s" a b c))
;; a= 1, b= 2, c=3
If a key is not present, it’s OK. No need to mark it optional:
(destructuring-bind (&key a b c)
(list :b 2 :a 1)
(format t "a= ~s, b= ~s, c=~s" a b c))
a= 1, b= 2, c=NIL
But we can’t have an input with undeclared keys, we should use &allow-other-keys:
;; DOESN'T WORK
(destructuring-bind (&key a b c)
(list :b 2 :a 1 :foo t)
;; ^^^ unknown
(format t "a= ~s, b= ~s, c=~s" a b c))
We get a clear error again:
Error while parsing arguments to DESTRUCTURING-BIND:
unknown keyword: :FOO; expected one of :A, :B, :C
Now we use &allow-other-keys:
(destructuring-bind (&key a b c &allow-other-keys)
(list :b 2 :a 1 :foo t)
(format t "a= ~s, b= ~s, c=~s" a b c))
;; a= 1, b= 2, c=NIL
That’s not all. Like in a defun lambda list, we can give
defaults, by using a cons cell (key default):
(destructuring-bind (&key a b (c 42))
(list :b 2 :a 1)
(format t "a= ~s, b= ~s, c=~s" a b c))
;; a= 1, b= 2, c=42
A destructuring lambda list can contain all the same keywords as a
macro lambda list, except for &environment. This includes &aux and
&body.
destructuring-bind’s structure is: a lambda-list, an input list, an
optional declaration using declare, one or many forms in the body.
The input list can be an expression that will be evaluated:
(destructuring-bind ((a &optional (b 'beta)) one two three)
`((alpha) ,@(list 1 2 3))
(list a b one two three))
;; => (ALPHA BETA 1 2 3)
If this gives you the will to do pattern matching, see pattern matching.
Predicates: null, listp, consp, atom
null is equivalent to not, but considered better style.
listp tests whether an object is a list or nil.
consp tests wether an object is a cons cell.
The empty list is not a cons, so (consp nil) is falsy, while
(listp nil) is truthy.
atom checks if its argument is an atom, in other words, if it isn’t
a cons. atom is also a type.
(atom '()) ;; => true
and see also all the sequences’ predicates.
list*, make-list
make-list allows to create a list of a given size, with an optional
initial element to fill it up:
(make-list 3 :initial-element "ta")
;; => ("ta" "ta" "ta")
(make-list 3)
;; => (NIL NIL NIL)
(fill * "hello")
;; => ("hello" "hello" "hello")
list* is similar to list in various aspects. it is handy to push
one (or many) element(s) in front of an existing list and to return a
new list:
(list* :foo (list 1 2 3))
;; => (:FOO 1 2 3)
(list* 'a 'b 'c '(d e f))
;; => (A B C D E F)
note that :foo was added in front of the list and the result list is flat, whereas in:
(list :foo (list 1 2 3))
;; => (:FOO (1 2 3))
we get a new list of two elements.
list*, like list, accepts a variable number of arguments. But a
difference is that the last element of the list is a cons cell with
the last 2 elements, denoted with a dotted pair below:
(list* 1 2 3)
;; => (1 2 . 3)
and this result is not a proper list: it is a suite of cons cells.
whereas with list:
(list 1 2 3)
;; => (1 2 3)
the last cons cell is the number 3 and nil, which is the termination for a proper list.
ldiff, tailp
If object is the same as some tail of list, tailp returns true; otherwise, it returns false.
If object is the same as some tail of list, ldiff returns a fresh list
of the elements of list that precede object in the list structure of
list; otherwise, it returns a copy of list.
What happens with a circular list? Check your implementation’s documentation. If it detects circularity it must return false.
member (elt, list)
Returns the tail of list beginning with the first element satisfying eqlity.
Accepts :test, :test-not, :key (functions or symbols).
(member 2 '(1 2 3))
;; (2 3)
Replacing objects in a tree: subst, sublis
subst and
subst-if search and replace occurrences of an element
or subexpression in a tree (when it satisfies the optional test):
(subst 'one 1 '(1 2 3))
;; => (ONE 2 3)
(subst '(1 . one) '(1 . 1) '((1 . 1) (2 . 2)) :test #'equal)
;; ((1 . ONE) (2 . 2))
sublis
allows to replace many objects at once. It substitutes the objects
given in alist and found in tree with their new values given in
the alist:
(sublis '((x . 10) (y . 20))
'(* x (+ x y) (* y y)))
;; (* 10 (+ 10 20) (* 20 20))
sublis accepts the :test and :key arguments. :test is a
function that takes two arguments, the key and the subtree.
(sublis '((t . "foo"))
'("one" 2 ("three" (4 5)))
:key #'stringp)
;; ("foo" 2 ("foo" (4 5)))
Sequences
lists and vectors (and thus strings) are sequences.
Note: see also the strings page.
Many of the sequence functions take keyword arguments. All keyword arguments are optional and, if specified, may appear in any order.
Pay attention to the :test argument. It defaults to eql. For
strings, use :equal.
The :key argument can be passed a function of one
argument. This key function is used as a filter through which the
elements of the sequence are seen. For instance, this:
(defparameter *list-of-pairs* '((1 2) (41 42)))
(find 42 *list-of-pairs* :key #'second)
;; => (41 42)
searches for an element in the sequence
whose second element equals 42, rather than for an element which equals 42
itself. If :key is omitted or nil, the filter is effectively the
identity function.
You can use a lambda function or any function that accepts one
argument.
Predicates: every, some, notany
every, notevery (test, sequence): they return nil or t, respectively, as
soon as one test on any set of the corresponding elements of sequences
returns nil.
some, notany (test, sequence): they return either the value of the test, or nil.
(defparameter foo '(1 2 3))
(every #'evenp foo)
;; => NIL
(some #'evenp foo)
;; => T
Example with a list of strings:
(defparameter *list-of-strings* '("foo" "bar" "team"))
(every #'stringp *list-of-strings*)
;; => T
(some (lambda (it)
(= 3 (length it)))
*list-of-strings*)
;; => T
Functions
See also sequence functions defined in
Alexandria:
starts-with, ends-with, ends-with-subseq, length=, emptyp,…
length (sequence)
elt (sequence, index) - find by index
beware, here the sequence comes first.
count (foo sequence)
Return the number of elements in sequence that match foo.
Additional paramaters: :from-end, :start, :end.
See also count-if, count-not (test-function sequence).
subseq (sequence start, [end])
(subseq (list 1 2 3) 0)
;; (1 2 3)
(subseq (list 1 2 3) 1 2)
;; (2)
However, watch out if the end is larger than the list:
(subseq (list 1 2 3) 0 99)
;; => Error: the bounding indices 0 and 99
;; are bad for a sequence of length 3.
To this end, use alexandria-2:subseq*:
(alexandria-2:subseq* (list 1 2 3) 0 99)
;; (1 2 3)
subseq is “setf”able, but only works if the new sequence has the same
length of the one to replace.
sort, stable-sort (sequence, test [, key function]) (destructive)
These sort functions are destructive, so one may prefer to copy the sequence with copy-seq before sorting:
(sort (copy-seq seq) #'string<)
Unlike sort, stable-sort guarantees to keep the order of the argument.
In theory, the result of this:
(sort '((1 :a) (1 :b)) #'< :key #'first)
could be either ((1 :A) (1 :B)), either ((1 :B) (1 :A)). On my tests, the order is preserved, but the standard does not guarantee it.
fill (sequence item &keys start end) (destructive)
fill is a destructive operation.
It destructively replaces the elements in sequence, in-between the start and end position, by item (a sequence).
(make-list 3)
;; (NIL NIL NIL)
(fill * :hello :start 1)
;; (NIL :HELLO :HELLO)
See also substitute.
find, position (foo, sequence) - get index
also find-if, find-if-not, position-if, position-if-not (test
sequence). See :key and :test parameters.
(find 20 '(10 20 30))
;; 20
(position 20 '(10 20 30))
;; 1
search and mismatch (sequence-a, sequence-b)
search searches in sequence-b for a subsequence that matches sequence-a. It returns the
position in sequence-b, or NIL. It has the from-end, end1, end2 and the usual test and key
parameters.
(search '(20 30) '(10 20 30 40))
;; 1
(search '("b" "c") '("a" "b" "c"))
;; NIL
(search '("b" "c") '("a" "b" "c") :test #'equal)
;; 1
(search "bc" "abc")
;; 1
mismatch returns the position where the two sequences start to differ:
(mismatch '(10 20 99) '(10 20 30))
;; 2
(mismatch "hellolisper" "helloworld")
;; 5
(mismatch "same" "same")
;; NIL
(mismatch "foo" "bar")
;; 0
substitute, nsubstitute[if,if-not]
Return a sequence of the same kind as sequence with the same elements,
except that all elements equal to old are replaced with new.
(substitute #\o #\x "hellx") ;; => "hello"
(substitute :a :x '(:a :x :x)) ;; => (:A :A :A)
(substitute "a" "x" '("a" "x" "x") :test #'string=)
;; => ("a" "a" "a")
nsubstitute is the “non-consing”, destructive version.
merge (result-type, sequence1, sequence2, predicate) (destructive)
The merge function is destructive.
destructively merge
sequence1withsequence2according to an order determined by the predicate.
(setq test1 (list 1 3 5 7))
(setq test2 (list 2 4 6 8))
(merge 'list test1 test2 #'<)
;; => (1 2 3 4 5 6 7 8)
Now look at test1:
test1
;; => (1 2 3 4 5 6 7 8)
;; at least on SBCL, your result may vary.
replace (sequence-a, sequence-b, &key start1, end1) (destructive)
Destructively replace elements of sequence-a with elements of sequence-b.
The full signature is:
(replace sequence1 sequence2
&rest args
&key (start1 0) (end1 nil) (start2 0) (end2 nil))
Elements are copied to the subsequence bounded by START1 and END1, from the subsequence bounded by START2 and END2. If these subsequences are not of the same length, then the shorter length determines how many elements are copied.
(replace "xxx" "foo")
"foo"
(replace "xxx" "foo" :start1 1)
"xfo"
(replace "xxx" "foo" :start1 1 :start2 1)
"xoo"
(replace "xxx" "foo" :start1 1 :start2 1 :end2 2)
"xox"
remove, delete (foo sequence)
Make a copy of sequence without elements matching foo. Has
:start/end, :key and :count parameters.
delete is the recycling version of remove.
(remove "foo" '("foo" "bar" "foo") :test 'equal)
;; => ("bar")
see also remove-if[-not] below.
remove-duplicates, delete-duplicates (sequence)
remove-duplicates returns a
new sequence with unique elements. delete-duplicates may modify the
original sequence.
remove-duplicates accepts the following, usual arguments: from-end
test test-not start end key.
(remove-duplicates '(:foo :foo :bar))
(:FOO :BAR)
(remove-duplicates '("foo" "foo" "bar"))
("foo" "foo" "bar")
(remove-duplicates '("foo" "foo" "bar") :test #'string-equal)
("foo" "bar")
mapping (map, mapcar, remove-if[-not],…)
If you’re used to map and filter in other languages, you probably want
mapcar. But it only works on lists, so to iterate on vectors (and
produce either a vector or a list, use (map 'list function vector).
mapcar also accepts multiple lists with &rest more-seqs. The
mapping stops as soon as the shortest sequence runs out.
map takes the output-type as first argument ('list, 'vector or
'string):
(defparameter foo '(1 2 3))
(map 'list (lambda (it) (* 10 it)) foo)
reduce (function, sequence). Special parameter: :initial-value.
(reduce '- '(1 2 3 4))
;; => -8
(reduce '- '(1 2 3 4) :initial-value 100)
;; => 90
Filter is here called remove-if-not.
Flatten a list (Alexandria)
With
Alexandria,
we have the flatten function.
Creating lists with variables
That’s one use of the backquote:
(defparameter *var* "bar")
;; First try:
'("foo" *var* "baz") ;; no backquote
;; => ("foo" *VAR* "baz") ;; nope
Second try, with backquote interpolation:
`("foo" ,*var* "baz") ;; backquote, comma
;; => ("foo" "bar" "baz") ;; good
The backquote first warns we’ll do interpolation, the comma introduces the value of the variable.
If our variable is a list:
(defparameter *var* '("bar" "baz"))
;; First try:
`("foo" ,*var*)
;; => ("foo" ("bar" "baz")) ;; nested list
`("foo" ,@*var*) ;; backquote, comma-@ to
;; => ("foo" "bar" "baz")
E. Weitz warns that “objects generated this way will very likely share structure (see Recipe 2-7)”.
Comparing lists
We can use sets functions.
Set
We show below how to use set operations on lists.
A set doesn’t contain the same element twice and is unordered.
Most of these functions have recycling (modifying) counterparts,
starting with “n”, e.g.nintersection and nreverse. The “n” is for
“non-consing”, a lisp parlance for “don’t create objects in memory”.
They all accept the usual :key
and :test arguments, so use the test #'string= or #'equal if you
are working with strings.
For more, see functions in
Alexandria:
setp, set-equal,… and the FSet library, shown in the next section.
intersection of lists
What elements are both in list-a and list-b ?
(defparameter list-a '(0 1 2 3))
(defparameter list-b '(0 2 4))
(intersection list-a list-b)
;; => (2 0)
Remove the elements of list-b from list-a (set-difference)
(set-difference list-a list-b)
;; => (3 1)
(set-difference list-b list-a)
;; => (4)
Join two lists with unique elements (union, nunion)
(union list-a list-b)
;; => (3 1 0 2 4) ;; order can be different in your lisp
nunion is the recycling, destructive version.
Remove elements that are in both lists (set-exclusive-or)
(set-exclusive-or list-a list-b)
;; => (4 3 1)
Add an element to a set (adjoin)
A new set is returned, the original set is not modified.
(adjoin 3 list-a)
;; => (0 1 2 3) ;; <-- nothing was changed, 3 was already there.
(adjoin 5 list-a)
;; => (5 0 1 2 3) ;; <-- element added in front.
list-a
;; => (0 1 2 3) ;; <-- original list unmodified.
You can also use pushnew, that modifies the list (see above).
Check if this is a subset (subsetp)
(subsetp '(1 2 3) list-a)
;; => T
(subsetp '(1 1 1) list-a)
;; => T
(subsetp '(3 2 1) list-a)
;; => T
(subsetp '(0 3) list-a)
;; => T
Arrays and vectors
Arrays have constant-time access characteristics.
They can be fixed or adjustable. A simple array is neither displaced
(using :displaced-to, to point to another array) nor adjustable
(:adjust-array), nor does it have a fill pointer (fill-pointer,
that moves when we add or remove elements).
A vector is an array with rank 1 (of one dimension). It is also a sequence (see above).
A simple vector is a simple array that is also not specialized (it
doesn’t use :element-type to set the types of the elements).
Create an array, one or many dimensions
make-array (sizes-list :adjustable bool)
adjust-array (array, sizes-list, :element-type, :initial-element)
Access: aref (array i [j …])
aref (array i j k …) or row-major-aref (array i) equivalent to
(aref i i i …).
The result is setfable.
(defparameter myarray (make-array '(2 2 2) :initial-element 1))
myarray
;; => #3A(((1 1) (1 1)) ((1 1) (1 1)))
(aref myarray 0 0 0)
;; => 1
(setf (aref myarray 0 0 0) 9)
;; => 9
(row-major-aref myarray 0)
;; => 9
Sizes
array-total-size (array): how many elements will fit in the array ?
array-dimensions (array): list containing the length of the array’s dimensions.
array-dimension (array i): length of the ith dimension.
array-rank number of dimensions of the array.
(defparameter myarray (make-array '(2 2 2)))
;; => MYARRAY
myarray
;; => #3A(((0 0) (0 0)) ((0 0) (0 0)))
(array-rank myarray)
;; => 3
(array-dimensions myarray)
;; => (2 2 2)
(array-dimension myarray 0)
;; => 2
(array-total-size myarray)
;; => 8
Vectors
Create with vector or the reader macro #(). It returns a simple
vector.
(vector 1 2 3)
;; => #(1 2 3)
#(1 2 3)
;; => #(1 2 3)
The following interface is available for vectors (or vector-like arrays):
vector-push(new-element vector): replace the vector element pointed to by the fill pointer bynew-element, then increment the fill pointer by one. Returns the index at which the new element was placed, or NIL if there’s not enough space.vector-push-extend(new-element vector [extension]): likevector-push, but if the fill pointer gets too large then the array is extended usingadjust-array.extensionis the minimum number of elements to add to the array if it must be extended.vector-pop(vector): decrement the fill pointer, and return the element that it now points to.fill-pointer(vector).setfable.
and see also the sequence functions.
The following shows how to create an array that can be pushed to and popped from arbitrarily, growing its storage capacity as needed. This is roughly equivalent to a list in Python, an ArrayList in Java, or a vector<T> in C++ – though note that elements are not erased when they’re popped.
CL-USER> (defparameter *v* (make-array 0 :fill-pointer t :adjustable t))
*V*
CL-USER> *v*
#()
CL-USER> (vector-push-extend 42 *v*)
0
CL-USER> (vector-push-extend 43 *v*)
1
CL-USER> (vector-pop *v*)
43
CL-USER> *v*
#(42)
CL-USER> (aref *v* 1) ; beware, the element is still there!
43
CL-USER> (setf (aref *v* 1) nil) ; manually erase elements if necessary
Transforming a vector to a list.
If you’re mapping over it, see the map function whose first parameter
is the result type.
Or use (coerce vector 'list).
Hash Table
Hash Tables are a powerful data structure, associating keys with values in a very efficient way. Hash Tables are often preferred over association lists whenever performance is an issue, but they introduce a little overhead that makes assoc lists better if there are only a few key-value pairs to maintain.
Alists can be used sometimes differently though:
- they can be ordered
- we can push cons cells that have the same key, remove the one in front and we have a stack
- they have a human-readable printed representation
- they can be easily (de)serialized
- because of RASSOC, keys and values in alists are essentially interchangeable; whereas in hash tables, keys and values play very different roles (as usual, see “Common Lisp Recipes” by Edmund Weitz for more).
Creating a Hash Table
Hash Tables are created using the function
make-hash-table. It
has no required argument. Its most used optional keyword argument is
:test, specifying the function used to test the equality of keys.
dict, and Rutils a #h reader macro.
Adding an Element to a Hash Table
If you want to add an element to a hash table, you can use gethash,
the function to retrieve elements from the hash table, in conjunction
with
setf.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'one-entry *my-hash*) "one")
"one"
CL-USER> (setf (gethash 'another-entry *my-hash*) 2/4)
1/2
CL-USER> (gethash 'one-entry *my-hash*)
"one"
T
CL-USER> (gethash 'another-entry *my-hash*)
1/2
T
With Serapeum’s dict, we can create a hash-table and add elements to
it in one go:
(defparameter *my-hash* (dict :one-entry "one"
:another-entry 2/4))
;; =>
(dict
:ONE-ENTRY "one"
:ANOTHER-ENTRY 1/2
)
Getting a value from a Hash Table
The function
gethash
takes two required arguments: a key and a hash table. It returns two
values: the value corresponding to the key in the hash table (or nil
if not found), and a boolean indicating whether the key was found in
the table. That second value is necessary since nil is a valid value
in a key-value pair, so getting nil as first value from gethash
does not necessarily mean that the key was not found in the table.
Getting a key that does not exist with a default value
gethash has an optional third argument:
(gethash 'bar *my-hash* "default-bar")
;; => "default-bar"
;; NIL
Getting all keys or all values of a hash table
The
Alexandria
library (in Quicklisp) has the functions hash-table-keys and
hash-table-values for that.
(ql:quickload "alexandria")
;; […]
(alexandria:hash-table-keys *my-hash*)
;; => (BAR)
Comparing hash-tables
Use equalp to compare the equality of hash-tables, element by
element. equalp is case-insensitive for strings. Read more in our
equality section.
Testing for the Presence of a Key in a Hash Table
The first value returned by gethash is the object in the hash table
that’s associated with the key you provided as an argument to
gethash or nil if no value exists for this key. This value can act
as a
generalized boolean if you want to test for the presence of keys.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'one-entry *my-hash*) "one")
"one"
CL-USER> (if (gethash 'one-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key exists"
CL-USER> (if (gethash 'another-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key does not exist"
But note that this does not work if nil is amongst the values that
you want to store in the hash.
CL-USER> (setf (gethash 'another-entry *my-hash*) nil)
NIL
CL-USER> (if (gethash 'another-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key does not exist"
In this case you’ll have to check the second return value of gethash which will always return nil if no value is found and T otherwise.
CL-USER> (if (nth-value 1 (gethash 'another-entry *my-hash*))
"Key exists"
"Key does not exist")
"Key exists"
CL-USER> (if (nth-value 1 (gethash 'no-entry *my-hash*))
"Key exists"
"Key does not exist")
"Key does not exist"
Deleting from a Hash Table
Use
remhash
to delete a hash entry. Both the key and its associated value will be
removed from the hash table. remhash returns T if there was such an
entry, nil otherwise.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'first-key *my-hash*) 'one)
ONE
CL-USER> (gethash 'first-key *my-hash*)
ONE
T
CL-USER> (remhash 'first-key *my-hash*)
T
CL-USER> (gethash 'first-key *my-hash*)
NIL
NIL
CL-USER> (gethash 'no-entry *my-hash*)
NIL
NIL
CL-USER> (remhash 'no-entry *my-hash*)
NIL
CL-USER> (gethash 'no-entry *my-hash*)
NIL
NIL
Deleting a Hash Table
Use
clrhash
to delete a hash table. This will remove all of the data from the hash table and return the deleted table.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'first-key *my-hash*) 'one)
ONE
CL-USER> (setf (gethash 'second-key *my-hash*) 'two)
TWO
CL-USER> *my-hash*
#<hash-table :TEST eql :COUNT 2 {10097BF4E3}>
CL-USER> (clrhash *my-hash*)
#<hash-table :TEST eql :COUNT 0 {10097BF4E3}>
CL-USER> (gethash 'first-key *my-hash*)
NIL
NIL
CL-USER> (gethash 'second-key *my-hash*)
NIL
NIL
Traversing a Hash Table: loop, maphash, with-hash-table-iterator
If you want to perform an action on each entry (i.e., each key-value pair) in a hash table, you have several options:
- of course,
loop, but also maphashwith-hash-table-iterator- as well as alexandria, serapeum and other third-party libraries.
=> please see our iteration page.
(loop :for k :being :the :hash-key :of *my-hash-table* :collect k)
;; (B A)
(maphash (lambda (key val)
(format t "key: ~A value: ~A~%" key val))
*my-hash-table*)
;; =>
key: A value: 1
key: B value: 2
NIL
Counting the Entries in a Hash Table
No need to use your fingers - Common Lisp has a built-in function to
do it for you:
hash-table-count.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (hash-table-count *my-hash*)
0
CL-USER> (setf (gethash 'first *my-hash*) 1)
1
CL-USER> (setf (gethash 'second *my-hash*) 2)
2
CL-USER> (setf (gethash 'third *my-hash*) 3)
3
CL-USER> (hash-table-count *my-hash*)
3
CL-USER> (setf (gethash 'second *my-hash*) 'two)
TWO
CL-USER> (hash-table-count *my-hash*)
3
CL-USER> (clrhash *my-hash*)
#<EQL hash table, 0 entries {48205F35}>
CL-USER> (hash-table-count *my-hash*)
0
Printing a Hash Table readably
With print-object (non portable)
It is very tempting to use print-object. It works under several
implementations, but this method is actually not portable. The
standard doesn’t permit to do so, so this is undefined behaviour.
(defmethod print-object ((object hash-table) stream)
(format stream "#HASH{~{~{(~a : ~a)~}~^ ~}}"
(loop for key being the hash-keys of object
using (hash-value value)
collect (list key value))))
gives:
;; WARNING:
;; redefining PRINT-OBJECT (#<STRUCTURE-CLASS COMMON-LISP:HASH-TABLE>
;; #<SB-PCL:SYSTEM-CLASS COMMON-LISP:T>) in DEFMETHOD
;; #<STANDARD-METHOD COMMON-LISP:PRINT-OBJECT (HASH-TABLE T) {1006A0D063}>
and let’s try it:
(let ((ht (make-hash-table)))
(setf (gethash :foo ht) :bar)
ht)
;; #HASH{(FOO : BAR)}
With a custom function (portable way)
Here’s a portable way.
This snippets prints the keys, values and the test function of a
hash-table, and uses alexandria:alist-hash-table to read it back in:
;; https://github.com/phoe/phoe-toolbox/blob/master/phoe-toolbox.lisp
(defun print-hash-table-readably (hash-table
&optional
(stream *standard-output*))
"Prints a hash table readably using ALEXANDRIA:ALIST-HASH-TABLE."
(let ((test (hash-table-test hash-table))
(*print-circle* t)
(*print-readably* t))
(format stream "#.(ALEXANDRIA:ALIST-HASH-TABLE '(~%")
(maphash (lambda (k v) (format stream " (~S . ~S)~%" k v)) hash-table)
(format stream " ) :TEST '~A)" test)
hash-table))
Example output:
#.(ALEXANDRIA:ALIST-HASH-TABLE
'((ONE . 1))
:TEST 'EQL)
#<HASH-TABLE :TEST EQL :COUNT 1 {10046D4863}>
This output can be read back in to create a hash-table:
(read-from-string
(with-output-to-string (s)
(print-hash-table-readably
(alexandria:alist-hash-table
'((a . 1) (b . 2) (c . 3))) s)))
;; #<HASH-TABLE :TEST EQL :COUNT 3 {1009592E23}>
;; 83
With Serapeum (readable and portable)
The Serapeum library
has the dict constructor, the function pretty-print-hash-table and
the toggle-pretty-print-hash-table switch, all which do not use
print-object under the hood.
CL-USER> (serapeum:toggle-pretty-print-hash-table)
T
CL-USER> (serapeum:dict :a 1 :b 2 :c 3)
(dict
:A 1
:B 2
:C 3
)
This printed representation can be read back in.
Thread-safe Hash Tables
The standard hash-table in Common Lisp is not thread-safe. That means that simple access operations can be interrupted in the middle and return a wrong result.
Implementations offer different solutions.
With SBCL, we can create thread-safe hash tables with the :synchronized keyword to make-hash-table: http://www.sbcl.org/manual/#Hash-Table-Extensions.
If nil (the default), the hash-table may have multiple concurrent readers, but results are undefined if a thread writes to the hash-table concurrently with another reader or writer. If t, all concurrent accesses are safe, but note that clhs 3.6 (Traversal Rules and Side Effects) remains in force. See also: sb-ext:with-locked-hash-table.
(defparameter *my-hash* (make-hash-table :synchronized t))
But, operations that expand to two accesses, like the modify macros (incf) or this:
(setf (gethash :a *my-hash*) :new-value)
need to be wrapped around sb-ext:with-locked-hash-table:
Limits concurrent accesses to HASH-TABLE for the duration of BODY. If HASH-TABLE is synchronized, BODY will execute with exclusive ownership of the table. If HASH-TABLE is not synchronized, BODY will execute with other WITH-LOCKED-HASH-TABLE bodies excluded – exclusion of hash-table accesses not surrounded by WITH-LOCKED-HASH-TABLE is unspecified.
(sb-ext:with-locked-hash-table (*my-hash*)
(setf (gethash :a *my-hash*) :new-value))
In LispWorks, hash-tables are thread-safe by default. But likewise, there is no guarantee of atomicity between access operations, so we can use with-hash-table-locked.
Ultimately, you might like what the cl-gserver library proposes. It offers helper functions around hash-tables and its actors/agent system to allow thread-safety. They also maintain the order of updates and reads.
Performance Issues: The Size of your Hash Table
The make-hash-table function has a couple of optional parameters
which control the initial size of your hash table and how it’ll grow
if it needs to grow. This can be an important performance issue if
you’re working with large hash tables. Here’s an (admittedly not very
scientific) example with CMUCL pre-18d on
Linux:
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
65
CL-USER> (hash-table-rehash-size *my-hash*)
1.5
CL-USER> (time (dotimes (n 100000)
(setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.27 seconds of real time
0.25 seconds of user run time
0.02 seconds of system run time
0 page faults and
8754768 bytes consed.
NIL
CL-USER> (time (dotimes (n 100000)
(setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.05 seconds of real time
0.05 seconds of user run time
0.0 seconds of system run time
0 page faults and
0 bytes consed.
NIL
The values for
hash-table-size
and
hash-table-rehash-size
are implementation-dependent. In our case, CMUCL chooses and initial
size of 65, and it will increase the size of the hash by 50 percent
whenever it needs to grow. Let’s see how often we have to re-size the
hash until we reach the final size…
CL-USER> (log (/ 100000 65) 1.5)
18.099062
CL-USER> (let ((size 65))
(dotimes (n 20)
(print (list n size))
(setq size (* 1.5 size))))
(0 65)
(1 97.5)
(2 146.25)
(3 219.375)
(4 329.0625)
(5 493.59375)
(6 740.3906)
(7 1110.5859)
(8 1665.8789)
(9 2498.8184)
(10 3748.2275)
(11 5622.3413)
(12 8433.512)
(13 12650.268)
(14 18975.402)
(15 28463.104)
(16 42694.656)
(17 64041.984)
(18 96062.98)
(19 144094.47)
NIL
The hash has to be re-sized 19 times until it’s big enough to hold 100,000 entries. That explains why we saw a lot of consing and why it took rather long to fill the hash table. It also explains why the second run was much faster - the hash table already had the correct size.
Here’s a faster way to do it: If we know in advance how big our hash will be, we can start with the right size:
CL-USER> (defparameter *my-hash* (make-hash-table :size 100000))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
100000
CL-USER> (time (dotimes (n 100000)
(setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.04 seconds of real time
0.04 seconds of user run time
0.0 seconds of system run time
0 page faults and
0 bytes consed.
NIL
That’s obviously much faster. And there was no consing involved
because we didn’t have to re-size at all. If we don’t know the final
size in advance but can guess the growth behaviour of our hash table
we can also provide this value to make-hash-table. We can provide an
integer to specify absolute growth or a float to specify relative
growth.
CL-USER> (defparameter *my-hash* (make-hash-table :rehash-size 100000))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
65
CL-USER> (hash-table-rehash-size *my-hash*)
100000
CL-USER> (time (dotimes (n 100000)
(setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.07 seconds of real time
0.05 seconds of user run time
0.01 seconds of system run time
0 page faults and
2001360 bytes consed.
NIL
Also rather fast (we only needed one re-size) but much more consing because almost the whole hash table (minus 65 initial elements) had to be built during the loop.
Note that you can also specify the rehash-threshold while creating a
new hash table. One final remark: Your implementation is allowed to
completely ignore the values provided for rehash-size and
rehash-threshold…
Alist
Definition
An association list is a list of cons cells.
Its keys and values can be of any type.
This simple example:
(defparameter *my-alist* (list (cons 'foo "foo")
(cons 'bar "bar")))
;; => ((FOO . "foo") (BAR . "bar"))
looks like this:
[o|o]---[o|/]
| |
| [o|o]---"bar"
| |
| BAR
|
[o|o]---"foo"
|
FOO
Construction
Besides constructing a list of cons cells like above, we can construct an alist following its dotted representation:
(setf *my-alist* '((:foo . "foo")
(:bar . "bar")))
Keep in mind that using quote doesn’t evaluate the expressions inside it.
The constructor pairlis associates a list of keys and a list of values:
(pairlis (list :foo :bar)
(list "foo" "bar"))
;; => ((:BAR . "bar") (:FOO . "foo"))
Alists are just lists, so you can have the same key multiple times in the same alist:
(setf *alist-with-duplicate-keys*
'((:a . 1)
(:a . 2)
(:b . 3)
(:a . 4)
(:c . 5)))
Access
To get a key, we have assoc (use :test 'equal when your keys are
strings, as usual). It returns the whole cons cell, so you may want to
use cdr or rest to get the value, or even assoc-value list key from Alexandria.
(assoc :foo *my-alist*)
;; (:FOO . "foo")
(cdr *)
;; "foo"
(alexandria:assoc-value *my-alist* :foo)
;; "foo"
;; (:FOO . "FOO")
;; It actually returned 2 values.
There is assoc-if, and rassoc to do a “reverse” search, to get a cons cell by its value:
(rassoc "foo" *my-alist*)
;; NIL
;; bummer! The value "foo" is a string, so use:
(rassoc "foo" *my-alist* :test #'equal)
;; (:FOO . "foo")
If the alist has repeating (duplicate) keys, you can use remove-if-not, for example, to retrieve all of them.
(remove-if-not
(lambda (entry)
(eq :a entry))
*alist-with-duplicate-keys*
:key #'car)
Insert and remove entries
The function acons adds a key with a given value to an existing
alist and returns a new alist:
(acons :key "key" *my-alist*)
;; => ((:KEY . "key") (:FOO . "foo") (:BAR . "bar"))
To add a key, we can push another cons cell:
(push (cons 'team "team") *my-alist*)
;; => ((TEAM . "team") (FOO . "foo") (BAR . "bar"))
We can use pop and other functions that operate on lists, like remove:
(remove :team *my-alist*)
;; ((:TEAM . "team") (FOO . "foo") (BAR . "bar"))
;; => didn't remove anything
(remove :team *my-alist* :key 'car)
;; ((FOO . "foo") (BAR . "bar"))
;; => returns a copy
Remove only one element with :count:
(push (cons 'bar "bar2") *my-alist*)
;; ((BAR . "bar2") (TEAM . "team") (FOO . "foo") (BAR . "bar"))
;; => twice the 'bar key
(remove 'bar *my-alist* :key 'car :count 1)
;; ((TEAM . "team") (FOO . "foo") (BAR . "bar"))
;; because otherwise:
(remove 'bar *my-alist* :key 'car)
;; ((TEAM . "team") (FOO . "foo"))
;; => no more 'bar
Update entries
Replace a value:
*my-alist*
;; => '((:FOO . "foo") (:BAR . "bar"))
(assoc :foo *my-alist*)
;; => (:FOO . "foo")
(setf (cdr (assoc :foo *my-alist*)) "new-value")
;; => "new-value"
*my-alist*
;; => '((:foo . "new-value") (:BAR . "bar"))
Replace a key:
*my-alist*
;; => '((:FOO . "foo") (:BAR . "bar")))
(setf (car (assoc :bar *my-alist*)) :new-key)
;; => :NEW-KEY
*my-alist*
;; => '((:FOO . "foo") (:NEW-KEY . "bar")))
In the
Alexandria
library, see more functions like hash-table-alist, alist-plist,…
Plist
What’s a plist
A property list is simply a list that alternates a key, a value, and so on, where its keys are keywords or symbols.
(defparameter my-plist (list :foo "foo" :bar "bar"))
A plist is a key-value store, like hash-tables. However, unlike hash-tables:
- a plist can store twice the same key. As such, it can be used as a queue (a “Last In First Out”), read below.
- a plist is inherently a (linked) list, and has the same performance
characteristics. For non-small data sets, use hash-tables.
- plists are OK for configuration variables, user settings, manipulating function arguments, small internal data structures…
- you can’t really use strings as keys.
The keys could be any other object, but if they are not comparable by
eq (the lowest-level equality function), like strings (that are
comparable with equal or string-equal), you won’t be able to get
them back with getf.
To be more precise, a plist first has a cons cell whose car is the
key, whose cdr points to the following cons cell whose car is the
value. For example our above plist looks like this:
[o|o]---[o|o]---[o|o]---[o|/]
| | | |
:FOO "foo" :BAR "bar"
In the example above, we used keywords for the keys: :foo,
:bar. This is just the most common way to define the keys. You can
use quoted symbols instead: 'foo, 'bar, but it’s just less
conventional.
Remember that if you use symbols for keys, then when you’ll want to access those keys from another package, you’ll need to use the fully-qualified symbol name. However, all keywords live in the same package so they always evaluate to themselves. It’s a bit simpler to use keywords.
Accessing data in a plist, using plists as queues
We access an element with getf:
(defparameter my-plist (list :foo "foo" :bar "bar"))
;; => (:FOO "foo" :BAR "bar")
(getf my-plist :foo)
;; => "foo"
Remember that we can’t set a :test keyword to getf. Keys must be
identical by eq for getf to get you the key. If you use strings
for the keys, it won’t work:
(defparameter not-ok-plist (list "foo" "this-is-foo" "bar" "this-is-bar"))
;; you get NIL, even if you can see "foo" is a key:
(getf not-ok-plist "foo")
;; => NIL
;; We didn't create a plist, but a list.
A plist can be used as a queue. If it has twice the same key, getf
takes the value of the first one (from left to right):
(defparameter my-plist (list :foo "lifo" :foo "foo" :bar "bar"))
;; ^^ ^^ twice the key :foo
(getf my-plist :foo)
;; => "lifo"
Removing elements from a plist
To remove an element from a plist, you’d use remf, which destructively changes the plist in place:
(defparameter my-plist (list :foo "foo" :bar "bar"))
;; => (:FOO "foo" :BAR "bar")
(remf my-plist :foo)
;; => T
my-plist
;; => (:bar "bar")
Adding elements to a plist
To add elements to a plist, you can use list* and append, which
are not destructive. They don’t modify the original plist in place.
Using list*, we add elements in front:
(defparameter my-plist (list :foo "foo" :bar "bar"))
(list* :baz "baz" my-plist)
;; => (:BAZ "baz" :FOO "foo" :BAR "bar")
my-plist
;; => (:FOO "foo" :BAR "bar")
;; the original plist was not modified.
Using append, we add elements to the end:
(defparameter my-plist (list :foo "foo" :bar "bar"))
(append my-plist '(:baz "baz"))
;; => (:FOO "foo" :BAR "bar" :BAZ "baz")
my-plist
;; => (:FOO "foo" :BAR "bar")
;; the original plist was not modified.
Use (setf my-plist (append …)) if you want to change the plist.
Setting elements of a plist
You can of course setf a place you got with getf. In that case, unlike
list* or append, setf will update the plist in place:
(defparameter my-plist (list :foo "foo" :bar "bar"))
;; => (:FOO "foo" :BAR "bar")
(getf my-plist :foo)
;; => "foo"
(setf (getf my-plist :foo) "foo!!!")
;; => "foo!!!"
my-plist
;; => (:FOO "foo!!!" :BAR "bar")
Structures
Structures offer a way to store data in named slots. They support single inheritance.
Classes provided by the Common Lisp Object System (CLOS) are more flexible however structures may offer better performance (see for example the SBCL manual).
Creation
Use defstruct:
(defstruct person
id name age)
At creation slots are optional and default to nil.
To set a default value:
(defstruct person
id
(name "john doe")
age)
Also specify the type after the default value:
(defstruct person
id
(name "john doe" :type string)
age)
We create an instance with the generated constructor make- +
<structure-name>, so make-person:
(defparameter *me* (make-person))
*me*
#S(PERSON :ID NIL :NAME "john doe" :AGE NIL)
note that printed representations can be read back by the reader.
With a bad name type:
(defparameter *bad-name* (make-person :name 123))
Invalid initialization argument:
:NAME
in call for class #<STRUCTURE-CLASS PERSON>.
[Condition of type SB-PCL::INITARG-ERROR]
We can set the structure’s constructor so as to create the structure without using keyword arguments, which can be more convenient sometimes. We give it a name and the order of the arguments:
(defstruct (person (:constructor create-person (id name age)))
id
name
age)
Our new constructor is create-person:
(create-person 1 "me" 7)
#S(PERSON :ID 1 :NAME "me" :AGE 7)
However, the default make-person does not work any more:
(make-person :name "me")
;; debugger:
obsolete structure error for a structure of type PERSON
[Condition of type SB-PCL::OBSOLETE-STRUCTURE]
Slot access
We access the slots with accessors created by <name-of-the-struct>- + slot-name:
(person-name *me*)
;; "john doe"
we then also have person-age and person-id.
Setting
Slots are setf-able:
(setf (person-name *me*) "Cookbook author")
(person-name *me*)
;; "Cookbook author"
Predicate
A predicate function is generated:
(person-p *me*)
T
Single inheritance
Use single inheritance with the :include <struct> argument:
(defstruct (female (:include person))
(gender "female" :type string))
(make-female :name "Lilie")
;; #S(FEMALE :ID NIL :NAME "Lilie" :AGE NIL :GENDER "female")
Note that the CLOS object system is more powerful.
Shorter slot access with symbol-macrolet
If you are accessing several slots within a single function the
special form symbol-macrolet can improve readibility, by creating
symbol macros which expand into forms with structure accessors:
(defstruct ship x-position y-position x-velocity y-velocity)
(defun move-ship (ship)
(symbol-macrolet
((x (ship-x-position ship))
(y (ship-y-position ship))
(xv (ship-x-velocity ship))
(yv (ship-y-velocity ship)))
(psetf x (+ x xv)
y (+ y yv))
ship))
Here the math involved in the move-ship function is easier to
read than if accessor functions were used.
Without symbol-macrolet
it looks like this:
(defun move-ship (ship)
(psetf (ship-x-position ship)
(+ (ship-x-position ship) (ship-x-velocity ship))
(ship-y-position ship)
(+ (ship-y-position ship) (ship-y-velocity ship)))
ship)
In this function all the accessors are not too hard to read, but with more complex operations it would quickly get cluttered.
Now, let’s try our function:
(move-ship (make-ship :x-position 1 :y-position 1 :x-velocity 2 :y-velocity 2))
;; #S(SHIP :X-POSITION 3 :Y-POSITION 3 :X-VELOCITY 2 :Y-VELOCITY 2)
Structures and with-slots
Though it is not mentioned in the standard, many modern implementations
of Common Lisp permit the use of the CLOS macro with-slots with
structures. In the standard with-slots itself is defined using
symbol-macrolet. At least SBCL and ECL will accept this:
(defstruct point x y)
(defvar p (make-point :x 2.3 :y -3.2))
(with-slots (x y) p
(list x y))
;; => (2.3 -3.2)
But do note that in the standard the behavior of the above use of
with-slots with a structure is called “unspecified.”
Limitations
After a change, instances are not updated.
If we try to add a slot (email below), we have the choice to lose
all instances, or to continue using the new definition of
person. But the effects of redefining a structure are undefined by
the standard, so it is best to re-compile and re-run the changed
code.
(defstruct person
id
(name "john doe" :type string)
age
email)
gives an error and we drop in the debugger:
attempt to redefine the STRUCTURE-OBJECT class PERSON
incompatibly with the current definition
[Condition of type SIMPLE-ERROR]
Restarts:
0: [CONTINUE] Use the new definition of PERSON, invalidating already-loaded code and instances.
1: [RECKLESSLY-CONTINUE] Use the new definition of PERSON as if it were compatible, allowing old accessors to use new instances and allowing new accessors to use old instances.
2: [CLOBBER-IT] (deprecated synonym for RECKLESSLY-CONTINUE)
3: [RETRY] Retry SLIME REPL evaluation request.
4: [*ABORT] Return to SLIME's top level.
5: [ABORT] abort thread (#<THREAD "repl-thread" RUNNING {1002A0FFA3}>)
If we choose restart 0, to use the new definition, we lose access to *me*:
*me*
obsolete structure error for a structure of type PERSON
[Condition of type SB-PCL::OBSOLETE-STRUCTURE]
There is also very little introspection. Portable Common Lisp does not define ways of finding out defined super/sub-structures nor what slots a structure has.
The Common Lisp Object System (which came after into the language) doesn’t have such limitations. See the CLOS section.
- structures on the hyperspec
- David B. Lamkins, “Successful Lisp, How to Understand and Use Common Lisp”.
Trees
Built-ins
A tree can be built with lists of lists.
For example, the nested list '(A (B) (C (D) (E))) represents the tree:
A
├─ B
╰─ C
├─ D
╰─ E
where (B), (D) and (E) are leaf nodes.
The functions tree-equal and copy-tree descend recursively into the car and
the cdr of the cons cells they visit.
See the functions subst and sublis above to replace elements in a tree.
FSet - immutable functional data structures
You may want to have a look at the FSet library (in Quicklisp) and its excellent documentation to use immutable data structures.
(ql:quickload "fset")
FSet provides the following collections:
maps, aka hash-tablesseqs, aka sequencessets, aka “unordered collection of values without duplicates”,bagsor multisets, aka sets that count how many occurences of a member is in the bag,- and more: “replay sets and maps”, “binary relations”, “tuples”, “interval sets” (ranges), “bounded sets”, and similar collections with strict (weak) ordering.
You can start reading its excellent documentation that includes a high level conceptual background, a tutorial, an API reference and a comparison with functional data structures from other ecosystems.
- FSet’s home and issue tracker: https://gitlab.common-lisp.net/fset/fset/
Sycamore - purely functional weight-balanced binary trees
Another fast, purely functional data structure library for Common Lisp is Sycamore.
It features:
- fast, purely functional Hash Array Mapped Tries (HAMT).
- fast, purely functional weight-balanced binary trees.
- interfaces for tree sets and maps (hash-tables).
- ropes
- purely functional pairing heaps
- purely functional amortized queues.
Controlling how much of data to print (*print-length*, *print-level*)
Use *print-length* and *print-level*.
They are both nil by default.
If you have a very big list, printing it on the REPL or in a
stacktrace can take a long time and bring your editor or even your
server down. Use *print-length* to choose the maximum of elements of
the list to print, and to show there is a rest with a ...
placeholder:
(setf *print-length* 2)
(list :A :B :C :D :E)
;; (:A :B ...)
And if you have a very nested data structure, set *print-level* to
choose the depth to print:
(let ((*print-level* 2))
(print '(:a (:b (:c (:d :e))))))
;; (:A (:B #)) <= *print-level* in action
;; (:A (:B (:C (:D :E))))
;; => the list is returned,
;; the let binding is not in effect anymore.
*print-length* will be applied at each level.
Reference: the HyperSpec.
Appendix A - which functions are destructive and which are not?
A destructive function alters the argument(s) it was given. For
example, the function nreverse is destructive:
(defparameter *hello* "hello")
(defun greet (s)
(print (nreverse s)))
(greet *hello*)
;; => "olleh"
;; What is *hello* now?
(print *hello*)
;; => "olleh"
;;
;; Ooops, the top-level variable was altered by a side-effect and that is not a good practice (at all).
How do you know which functions are destructive?
- all
nsomething functions are destructive:nreverse,nsubstitute… “n” means “non-consing”, the function will not allocate any new cons cell (it won’t create new objects in memory), so it might reuse the original sequence, and alter it in place.nstring-upcase,nstring-downcase,nstring-capitalizenunion,nintersection,nset-difference,nset-exclusive-ornbutlastnsubst[-if, -if-not],nsublis,nsubstitue[-if, -if-not]- each
n-something function has its non-destructive counterpart, that you should prefer using.
sortandstable-sortare destructive functions, so ismerge, so it’s best practice to usecopy-listorcopy-seqbefore calling one of them.- the
delete[-*]functions are destructive (removeisn’t destructive) (setf (nth ... ...) ...)is obviously destructive.replace,fillare destructivevector-pushcan be destructiveremprop,remfmap-into
Also:
pop,push: they are not destructive in the sense that they don’t alter conses, but they change the car of the place they pop or push from/to.
Appendix B - generic and nested access of alists, plists, hash-tables and CLOS slots
The solutions presented below might help you getting started, but keep in mind that they’ll have a performance impact and that error messages will be less explicit.
- the access library (battle tested, used by the Djula templating system) has a generic
(access my-var :elt)(blog post). It also hasaccesses(plural) to access and set nested values. - rutils as a generic
generic-eltor?,
Appendix C - accessing nested data structures
Sometimes we work with nested data structures, and we might want an
easier way to access a nested element than intricated “getf” and
“assoc” and all. Also, we might want to just be returned a nil when
an intermediary key doesn’t exist.
The access library given above provides this, with (accesses var key1 key2…).
Appendix D - Collections Type Hierarchy
Solid nodes are concrete types, while dashed ones are type aliases. For example, 'string is an alias for an array of characters of any size, (array character (*)).
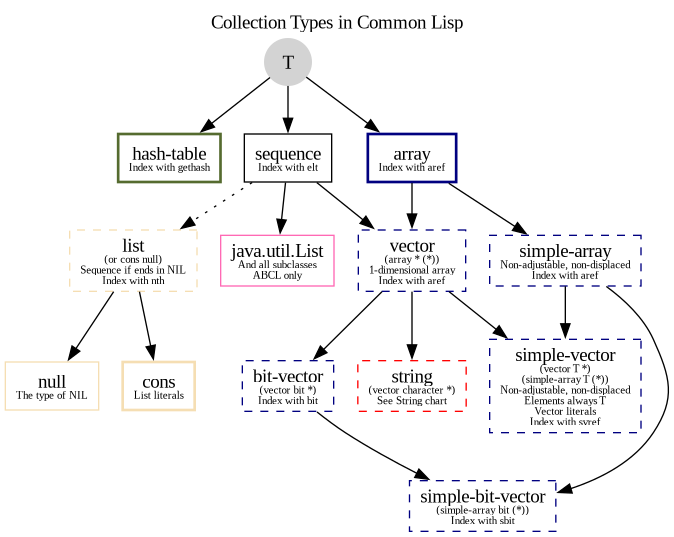
See also
- the Pretty Printer:
*print-length*,*print-right-margin*,pprint-tabularetc.
Page source: data-structures.md